
排序
写在前面
总述
- 本文使用的线性表大部分为数组
- 所有算法按升序对线性表进行排序
排序的稳定性
如果排序前,有2个相等的数(设为a,b,a在前,b在后,不一定挨在一起)。在排序后,这两个数仍然是a在前,b在后,则称这个排序算法是稳定的。
- 稳定排序算法:插入排序,冒泡排序,归并排序,基数排序
- 不稳定排序算法:选择排序,快速排序,希尔排序
插入排序
简要介绍
插入排序(InsertionSort),一般也被称为直接插入排序
插入排序是稳定的:比如1 5 2 3 5 2按升序排序,对于2和5来说,排在前面的肯定会比排在后面的先插入,前后顺序是不变的。
算法思路
- 基本思路是将一个数插入到一个已经排好序的表中。
- 拿数组举例,从第二个开始,与前面的值作比较,一碰到比自己小的数就插在这个数的后面(升序)。
- 我的思路是,对于一个没有插入的数,与它前面的数依次比较,如果前面的更大,就交换这两个数,直到遇见更小的或者到底。
- 比如,假设1 2 3 0此时将要插入0,首先与3比较,发现3更大,交换:
1 2 0 3;
接着与2比较,同理,1 0 2 3;
最后与1比较,0 1 2 3;
接着发现前面到头了,停止比较,结束对0的“插入”。
时间复杂度分析
最坏的情况是O(n^2)
代码
//将第n个数插入到前面n-1个排好序的数组中
void insertionSort(int a[], int len) {
for (int i = 1; i < len; i++) { //最外层遍历第二个及后面的数
for (int j = i; j > 0; j--) { //与该数前面的数做比较
if (a[j] < a[j - 1]) { //升序
swap(a[j - 1], a[j]); //与该数前面更大的数做交换。相当于把它提出来,再让大于它的所有元素后移一位,再塞过去
}
else
break; //碰到比自己小的了,就停止交换,相当于插在它的前面
}
}
}
选择排序
简要介绍
选择排序是一种简单直观的排序算法,无论什么数据进去都是 O(n²) 的时间复杂度。所以用到它的时候,数据规模越小越好。唯一的好处可能就是不占用额外的内存空间了吧。 ——菜鸟教程
算法思路
- 基本思路是,对于第i个数,找到它后面的最小值(升序),然后与这个数交换。
- 可以理解为我假定某个数就在这个位置上面,然后就到后面去找这个数,找到后就换到这里(不知道我的意思传达到没)。
- 对于链表来说,我们需要三个指针变量,一个用来寻找最小值,一个用来保存最小值的位置,一个用来保存排好序的部分后面的(第一个)位置。
- 从第一个结点开始,往后寻找最小值(包括第一个结点),找到后交换;然后对第二个结点进行操作,以此类推。
时间复杂度分析
O(n²)
代码
struct node {
int data;
node* link;
};
//选择排序
void selectionSort(node *head) {
node* p = head;//p用于往后遍历每一个元素
node* q = head; //q用于指向排好序的末尾的结点的后一个结点
node* t = head; //t用于指向最小元素
p = q->link;
while (q->link != NULL && p != NULL) {
t = q; //从q开始
while (p != NULL) { //往后遍历所有结点
if (p->data < t->data) { //如果找到了更小的元素
t = p;//t指向最小元素
}
p = p->link;//继续向后遍历
}//此时已经找到了最小的值所在的结点,由t指向
if (t != q) {//最小值在后面的话,就交换两个结点的值
swap(t->data, q->data);
}
q = q->link;//排好序后,更新末尾结点
p = q->link;//因为t指向q,所以p从q的下一个开始
}
}
冒泡排序
简要介绍
冒泡排序(Bubble Sort)也是一种简单直观的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢"浮"到数列的顶端。 ——菜鸟教程
这是一个我们非常熟悉的排序方法,在过程上就像是把大一点(升序)的值往后移,给人的感觉很像选择排序。
算法思路
- 从第一个元素开始,比较所有的相邻元素,如果前者大于(升序)后者,就交换他们,直到最后一个元素。
- 这一轮完成后,最大的元素一定到了最末尾的位置上。所以第二轮,我们还是从第一个元素开始两两比较,然后在倒数第二个元素停止。
时间复杂度分析
O(n²)
代码
void bubbleSort(int a[11], int n) {
bool isS = false; //用于判断一次循环中是否有交换过,没有的话说明后面的都是有序的,不用再进行下去了。
for (int i = 0; i < n; i++) {
isS = false;
for (int j = 0; j < n - i - 1; j++) { //从n开始往前的i个数已经排好了
if (a[j - 1] > a[j]) { //升序
swap(a[j - 1], a[j]); //交换两个数
isS = true; //交换过了
}
}
if (!isS) break;
}
}
归并排序
简要介绍
归并排序(Merge sort)是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。 ——菜鸟教程
算法思路
- 算法总体分为两步:分组与合并组
- 分组就是不断地把一个组“切”成两半,当然,如果为奇数的话,会出现某个组比另一个组多一个元素,不过这没有什么影响。最后分完组的结果是:每一个组都是有1个或者0个元素。
- 合并组就是把两个组(有序)合并成一个有序的组。由于合并的是两个有序的组,所以直接从这两个组开头开始比较,然后借用一个中间数组储存排好序的结果。
- 可以理解为,桌上有两堆有序的牌,我们要把它们合成一堆有序的牌,所以要找块地方放新牌堆。
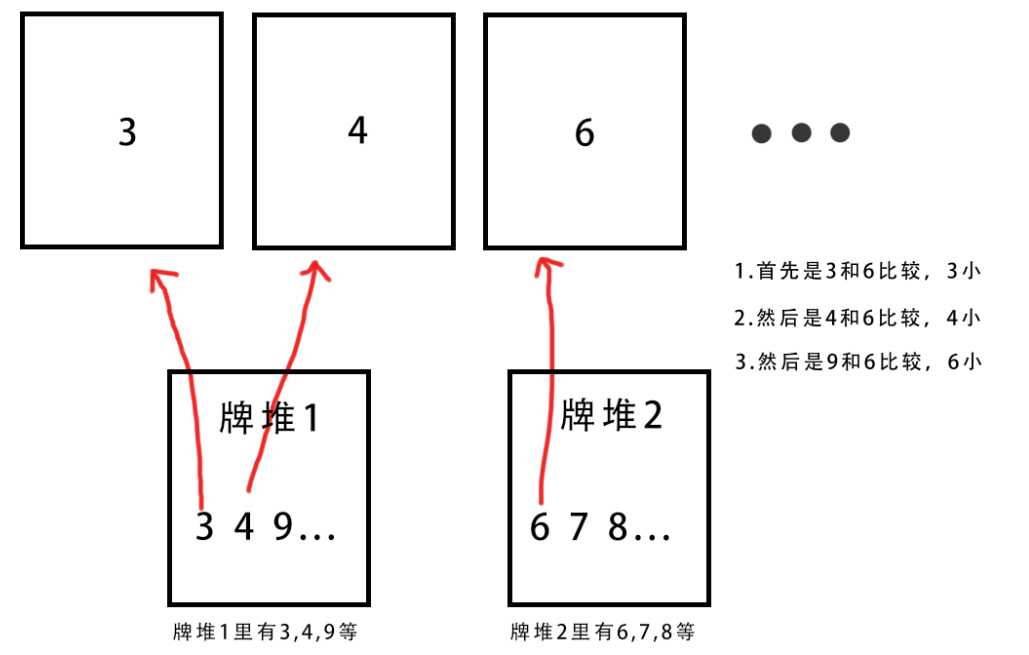
时间复杂度分析
O(nlogn)
代码
//将数组a的beg到mid和mid+1到end的两组通过数组b合并到一起。传入的是数组下标,而不是个数。
void merge(int* a, int* b, int beg, int mid, int end) {
int i = beg, //i 是遍历前半部分数组,上限是mid
j = mid + 1, //j 是第二个数组起始的下标,上限是end
k = beg; //k 是遍历数组b,上限是end
while (i <= mid && j <= end) { //开始合并,i、j记录比较到这两半数组的哪里了
if (a[i] < a[j]) //看这两部分中,哪个值更小,如果a[i]更小就把它塞到b[k]里面去。
b[k++] = a[i++]; //++直接放在[]里,不用单独写,更简洁
else
b[k++] = a[j++]; //如果a[j]更小就把它塞到b[k]里面去。
}
while (i <= mid) b[k++] = a[i++]; //如果j到顶了,即后半部分全部塞进去了,那么前半部分直接按顺序填入即可
while (j <= end) b[k++] = a[j++]; //同理
for (i = beg; i <= end; i++)
a[i] = b[i];
}
void mergeSort(int a[], int b[], int begin, int end) {
int mid;
if (begin < end) {
mid = begin + (end - begin) / 2; //二分,求出中间的下标
mergeSort(a, b, begin, mid); //左
mergeSort(a, b, mid + 1, end); //右
merge(a, b, begin, mid, end); //合并
}
}
自然归并排序
简要介绍
自然归并排序是针对归并排序做的改进,它把已经有序的分成一组,所有数据分完后就把它们合并。这样可以更好地利用已有的信息。
算法思路
- 首先就是分组,以升序来说,一段升序的数结束的标志是它后面的数小于这个数。
- 怎么分组解决了,接下来解决的是怎么保存这些组。我们肯定不可能去创建一堆新的数组
int pos[n]专门储存这些数。有个非常巧妙的办法,就是记录每一组的起始元素的下标,这样就相当于分组了。 - 分组完成后,循环 (组数-1) 次,每次合并前两个组(跟归并排序一样地合并),最后排序就完成了。
- 代码注释得比较详细,应该能看懂。。。吧。
时间复杂度分析
O(nlogn)
代码
//利用pos数组记录长度为a的数组的升序的“断掉的地方”,
//pos记录的是升序的起始位置,如果需要上一个组的结束位置,减一即可
//n是a 的长度
int getPos(int a[], int pos[]) {
int tem = 1; //pos要记录的下标从1开始
pos[0] = 0; //首先开头记录为0,因为第一个组的起始位置一定是0
for (int i = 0; i < N - 1; i++) {//注意此处的 n - 1 ,因为是i+1,防止越界!
if (a[i] > a[i + 1]) { //举例:1 2 3 5 0 1 2 3 中,从5到0就是个断点,此时5 > 0,记录好0的位置
pos[tem++] = i + 1;//记录非升序的部分,这样就可以分成多个升序的组,通过pos记录下标
}
}
return tem; //返回pos的尾标
}
//将数组a的beg到mid和mid+1到end的两组通过数组b合并到一起
void merge(int* a, int* b, int beg, int mid, int end) {
int i = beg, //i 是遍历前半部分数组,上限是mid
j = mid + 1, //j 是第二个数组起始的下标,上限是end
k = beg; //k 是遍历数组b,上限是end
while (i <= mid && j <= end) { //开始合并,i、j记录比较到这两半数组的哪里了
if (a[i] < a[j]) //看这两部分中,哪个值更小,如果a[i]更小就把它塞到b[k]里面去。
b[k++] = a[i++]; //++直接放在[]里,不用单独写,更简洁
else
b[k++] = a[j++]; //如果a[j]更小就把它塞到b[k]里面去。
}
while (i <= mid) b[k++] = a[i++]; //如果j到顶了,即后半部分全部塞进去了,那么前半部分直接按顺序填入即可
while (j <= end) b[k++] = a[j++]; //同理
for (i = beg; i <= end; i++) //将临时数组copy回去
a[i] = b[i];
}
//a[]:原始数组,b[]:临时数组
void mergeSort(int a[],int b[]) {
int pos[N]; //定义pos数组
int posLen = getPos(a, pos); //生成pos数组并获取其长度
//总需的merge次数为:组数(posLen) - 1。
for (int i = 0; i < posLen - 2; i++) { //排序
merge(a, b, pos[0], pos[i + 1] - 1, pos[i + 2] - 1);
}//这个过程完毕后,还会剩下最后两个组
merge(a, b, pos[0], pos[posLen - 1] - 1, N - 1); //合并最后的2组
}
快速排序
简要介绍
快速排序是由东尼·霍尔所发展的一种排序算法。
快速排序使用分治法(Divide and conquer)策略来把一个串行(list)分为两个子串行(sub-lists)。
快速排序又是一种分而治之思想在排序算法上的典型应用。本质上来看,快速排序应该算是在冒泡排序基础上的递归分治法。
——菜鸟教程
算法思路
- 首先从要排序的数中选出一个基准数(一般为第一个数)
- 然后把所有比基准数小(升序)的数放在它的左边,比基准数大的数放在它的右边。具体方法为:
- 假设有个哨兵a(沿用《啊哈!算法》),它从数列末尾开始往前找,遇到比基准数小的数就停下来。
- 接下来,哨兵b从开头出发,往末尾走,遇到比基准数大的数就停下来。
- 交换这两个哨兵的数,然后让他们接着走下去。
- 在这整个过程中,当两个哨兵相遇时,把基准数与相遇的地方的数交换,这次循环就结束了。
- 最后递归地对基准数两边的数做相同的操作,直到数列只剩1个元素。
时间复杂度分析
快速排序的最坏运行情况是 O(n²),比如说顺序数列的快排。但它的平摊期望时间是 O(nlogn),且 O(nlogn) 记号中隐含的常数因子很小,比复杂度稳定等于 O(nlogn) 的归并排序要小很多。所以,对绝大多数顺序性较弱的随机数列而言,快速排序总是优于归并排序。 ——《算法艺术与信息学竞赛》
代码
//a[]:传入的数组,low:数组起始下标,high:数组结束下标
void quickSort(int a[], int low, int high) {
if (high <= low) return; //当数组只剩下一个时返回
int i = low, j = high, key = a[low]; //i、j为哨兵,key为基准值
while (true) {
while (a[j] >= key) { //先从右往左找比基准值小的
j--; //从后往前找
if (j == low) break; //两个哨兵相遇就停止
}
while (a[i] <= key) { //再从左往右找比基准值大的
i++; //从前往后找
if (i == high) break; //两个哨兵相遇就停止
}
if (i >= j) break; //两个哨兵相遇就停止整个寻找流程
swap(a[i], a[j]); //交换哨兵jio下的数
}
a[low] = a[j]; //交换这两个数,可以直接用swap函数
a[j] = key; //swap(a[low], a[j]);
quickSort(a, low, j - 1); //对左边进行相同操作
quickSort(a, j + 1, high); //对右边进行相同操作
}
希尔排序
简要介绍
希尔排序,也称递减增量排序算法,是插入排序的一种更高效的改进版本。但希尔排序是非稳定排序算法。
希尔排序是基于插入排序的以下两点性质而提出改进方法的:
- 插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率;
- 但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位;
简单来说,因为插入排序一次只移动一位,如果这个数距离它本来的位置过远,就会耗费大量时间。所以我们需要让它一次多跳几位。
算法思路
- 主要思路就是分组,对每组进行插入排序。然后减小组距,接着做插入排序,最后组距为1(即整个数组为一组)时,再进行一次插入排序就结束了。
- 我们一般把最开始的组距设为数组长度的一半,然后让它自除以2。
- 接着对每一组做插入排序
- 重复2,3步
时间复杂度分析
O(n^1.5)
下界是O(nlogn)
代码
template<class T>
void shellSort(T a[], int length) { // a[]:传入的要排序的数组, length:数组长度
//int length = sizeof(a) / sizeof(a[0]); // 求数组长度
// interval作为分组间距,每次自除以2,最后肯定会变成1和0
for (int interval = length / 2; interval; interval /= 2) {
// arrayNum作为组数,同时也作为起始位置。遍历每组,在组内排序
for (int arrayNum = 0; arrayNum < interval; arrayNum++) {
/*-—--—-—-—-—-—--—-—-—--—-—以下是插入排序-—--—-—-—--—-—-—--—-—-—-*/
// numBeSort:将要插入的数,从第一个数开始
// 考虑到下面的是用a[numBeSort] > a[numBeSort + interval],所以是numBeSort + intrval < length
// 每次加interval就算是分组了
for (int numBeSort = arrayNum; numBeSort + interval < length; numBeSort += interval) {
// 采用前面的插入排序方法
for(int i = numBeSort; i >= 0; i -= interval) {
if (a[i + interval ] < a[i]) // 把小的往前面插,升序
swap(a[i], a[i + interval]);
}
}
}
}
}
基数排序
简要介绍
基数排序是一种非比较型整数排序算法,其原理是将整数按位数切割成不同的数字,然后按每个位数分别比较。由于整数也可以表达字符串(比如名字或日期)和特定格式的浮点数,所以基数排序也不是只能使用于整数。 ——菜鸟教程
总之就是通过比较同位上的数来达成排序。
算法思路
- 从个位开始比较(这样更方便计算机操作,毕竟现在是人去适配计算机),一直比到最高位。
- 从0到9一共10个桶,将这些数按照个位的数放入这些桶内
- 然后从0桶开始,以此放回原数列。
- 接着按照十位、百位…位数不足的在前面补零(比如23补零成0023)。
- 最高位排完后,整个排序过程就完成了。
时间复杂度分析
O(n)
代码
注:未回收开辟的内存
constexpr auto N = 10; //有10个桶,0~9;
constexpr auto DIG = 4; //最大位数为4;
struct node {
int data;
node* link;
};
//作用:获取a的倒数第n + 1位数字
int getNNum(int a, int n) {
while (n--)
a = a / N; //这里的N可以是10,为了使程序统一
return a % N;
}
//基数排序
void radixSort(node* arr) {
if (arr == NULL) return;
node* p = arr;
for (int i = 0; i < DIG; i++) { //排4次
node* head[N] = { NULL }; //十个桶的头结点 一定要放在里面,相当于初始化!每次都要初始化!
node* tail[N] = { NULL }; //十个桶的尾结点
p = arr; //从开头开始
while (p != NULL) { //入桶,这一段是非常经典的创建新结点然后加到链表末尾的操作
int temp = getNNum(p->data, i); //获取本轮次对应的位数的值
if (head[temp] == NULL) { //如果头结点为空
head[temp] = new node; //开辟头结点
head[temp]->data = p->data; //赋值
head[temp]->link = NULL; //赋值
tail[temp] = head[temp]; //更新尾结点
}
else {
node* q = new node; //开辟一个新结点
q->data = p->data; //对新结点赋值
q->link = NULL; //同上
tail[temp]->link = q; //连接尾结点
tail[temp] = q; //更新尾结点
}
p = p->link; //指向下一个数
}
//出桶,此处用覆盖式地放回原链表
p = arr;
for (int j = 0; j < N; j++) { //j就是桶对应的数
node* tmp = head[j];
while (tmp != NULL && p != NULL) {
p->data = tmp->data; //覆盖式插回
p = p->link;
tmp = tmp->link;
}
}
}
}